Link: https://covid19researchdatabase.org/70
Brief description of the COVID-19 Research Database initiative and data
The goal of the COVID-19 Research Database70 is to provide public health and policy researchers with access to RWD to better understand and combat the COVID-19 pandemic. The COVID-19 Research Database was born out of the urgent need to better understand the effects of COVID-19 and streamline the challenges of managing data provider partnerships, patient privacy, and technological integration.
Set up in the spring of 2020, the COVID-19 Research Database consortium is a cross-industry, cross-sector collaborative composed of institutions that donate technology services, health care expertise, and de-identified data in the US. The data repository constructed by the consortium contains integrated, linked data sets from multiple sources, enabling public health and policy researchers to access RWD. The collaborative includes: Medidata (providing the engineering, hosting, and technical services), Datavant (providing the linking software), data providers (e.g., Healthjump, Change, Veradigm, OfficeAlly, and others), academic and non-profit partners (including Health Care Cost Institute), and technology partners (including Snowflake).
In all, 12 de-identified US data sets have been donated by consortium institutions and are integrated into a single repository. Data were de-identified using a technology that replaces identifiable patient information with an encrypted token; patients with data across select multiple data sources were linked using this tokenization process. Linking data in this way allows researcher access to a wide breadth of patient data. The data sets are loaded into cloud database management software, and researchers access a secure workspace containing analytical tools (e.g., SAS, SPSS, R, Python).
Records from 250 million unique persons and over 5 million patients with COVID-19 were loaded onto the platform. Data types include medical claims, pharmacy claims, EHRs, demographics, life insurance claims, consumer data, and mortality records. The longitudinal, patient-level data sets are HIPAA-compliant (de-identified and limited). The linkages among the data sets allow for a more complete view of clinical care. The linking techniques are also privacy-preserving. All included data are structured. Depending on the source, data are refreshed weekly to quarterly.
Each consortium member is represented on a governance committee that makes consortium-level decisions and ensures all stakeholder interests are protected. Expert advisory groups are consulted on privacy, patient advocacy, legal issues, and strategy. A scientific steering committee, comprised of academics and clinical researchers, reviews research proposals for scientific rigor and peer-review standards. The database itself can be accessed by academic, scientific, and medical researchers. Although the researchers themselves may come from any sector, the projects themselves must be non-profit, non-commercial, and related to COVID-19.
Data workflow and technology features are outlined below in Figure 5.2 and Figure 5.3.71
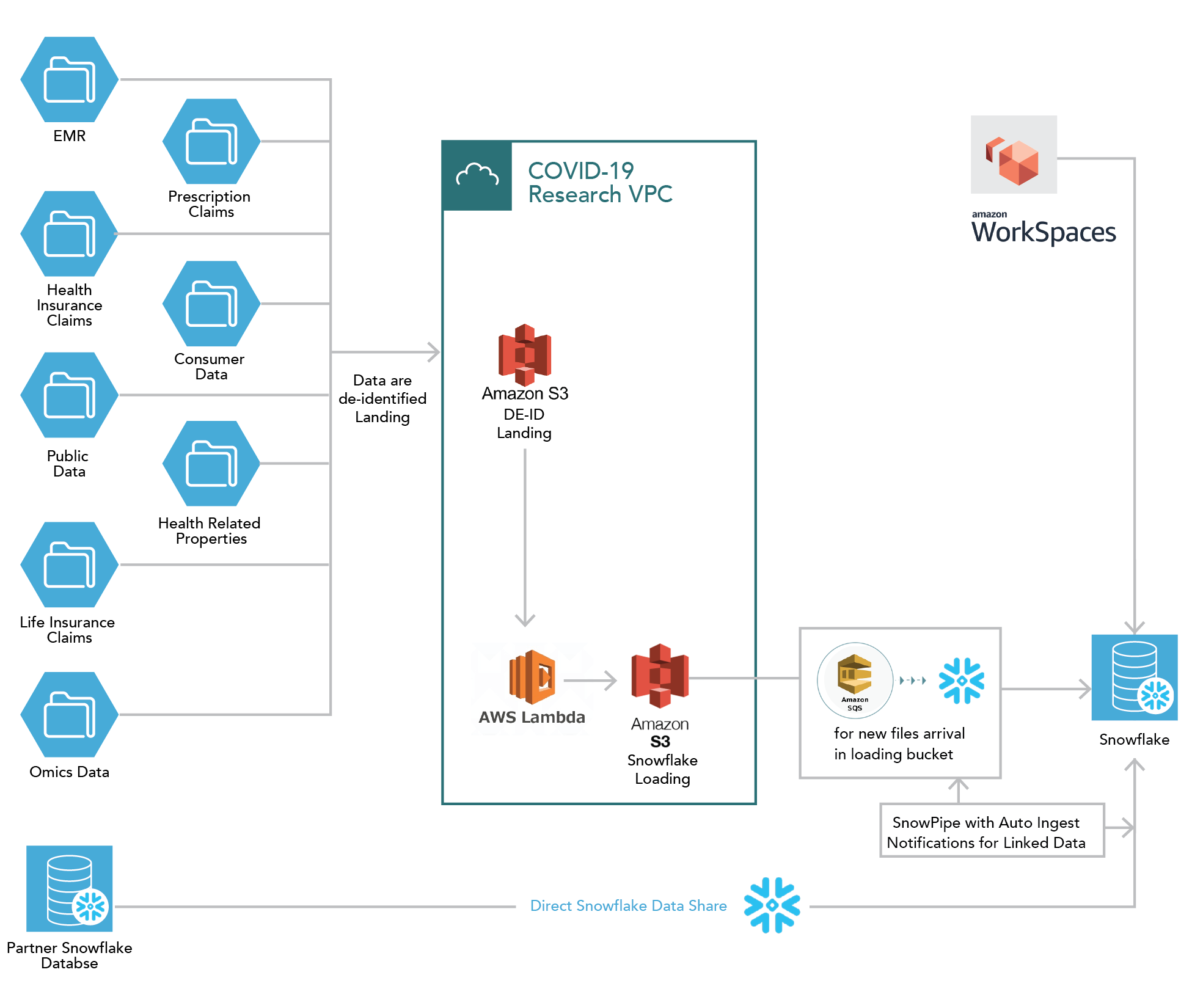
Figure 5.2. COVID-19 Research Database — Data Workflow
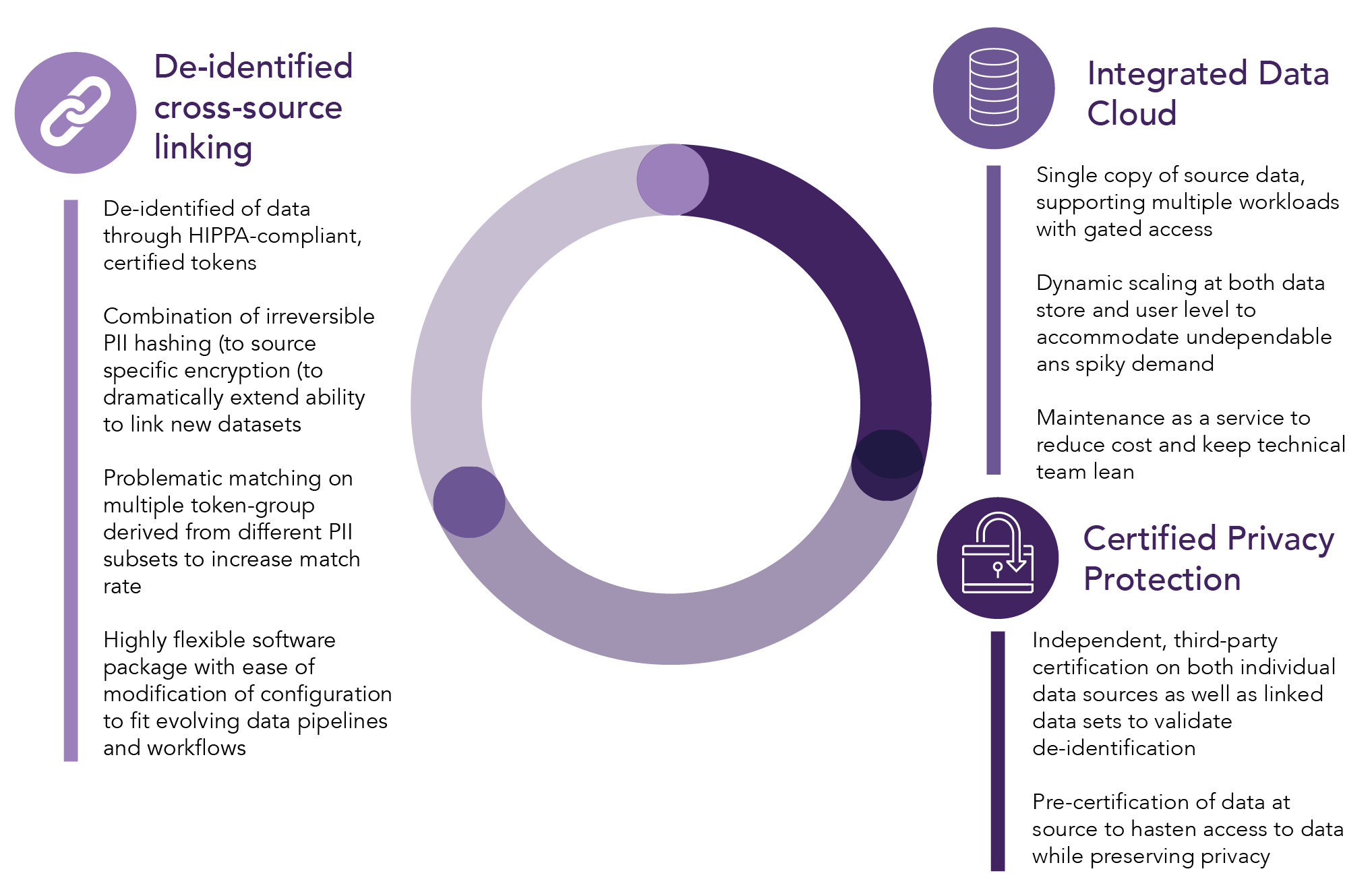
Figure 5.3. Covid-19 Research Database — Technology Features
Researchers interested in accessing the database can submit a proposal to the Scientific Steering Committee. After scientific, privacy, and governance review, approved researchers have access to de-identified data, a knowledge base for the data sets, and tools (including R, Python, and SAS) at no cost. Record-level joins can be made among data sets. All linked data sets are de-identification certified before release for research use. Data cannot leave the secure environment, but an analytical report may be exported to use in published findings. All results must be made publicly available, preferably through peer-reviewed publications.
COVID-19 Research Database observational research: Dynamic, extensible, scalable data integration design
Consortium publications have ranged from disease understanding (e.g., risk factors) to resource utilization (e.g., impact on preventive care) and epidemiology (e.g., social determinants of risk). Examples of projects that have been conducted include prediction of severity of COVID-19 infection, COVID-19 and social determinants of health, risk factors for COVID-19 infection, and implications of policies related to the COVID-19 pandemic. Potential longer-term projects include understanding the spread of COVID-19 variants, post-vaccination health implications, and understanding of long COVID. Findings are intended for practitioners, to help them understand the disease, as well as policy makers and public health officials, to help drive informed decision-making and improved understanding of the impact on different populations.
COVID-19 Research Database case studies
The below examples of peer-reviewed publications highlight the range of research topics addressable by the diverse array of data assets available in the consortium, in topics including risk factors, testing patterns, resource utilization, and primary care impacts:
- Racial Disparities in Ischemic Stroke Among Patients with COVID-19 in the United States72
- Assessment of Filled Buprenorphine Prescriptions for Opioid Use Disorder During the Coronavirus Disease 2019 Pandemic73
- Charges of COVID-19 Diagnostic Testing and Antibody Testing Across Facility Types and States74
- Trends in Filled Naloxone Prescriptions Before and During the COVID-19 Pandemic in the United States75
Beyond data diversity, it is the ability to join disparate data sets, in a privacy-compliant manner, that sets apart the COVID-19 Research Database consortium. One example of this is ongoing work by researchers from Northwestern University, Johns Hopkins, and Datavant exploring the intersection of race, income, and mortality due to COVID-19. Traditional RWD sources, such as EHR and insurance claims data, are often missing detailed information on patient attributes and mortality. To address this gap, a medical claims data source, Office Ally, was augmented with mortality data and consumer data. Mortality data were obtained from a curated source drawn from government agencies, online newspapers, funeral homes, online memorials, direct submissions, and other sources that collectively cover over 80% of annual US deaths. Data on demographics and income were obtained from a consumer data source, AnalyticsIQ, with consumer attributes across >120 million households. In the words of the authors, “the key elements utilized in the study were (i) fact of death, which was pulled from the mortality data set, (ii) the physician diagnosis information from the medical claims data, and (iii) the racial and income attributes drawn from the consumer data.”76 Through the consortium, this study was able to match patients across the 3 data sources, confirm privacy-preservation of the linked data, leverage confirmed mortality data, and incorporate modeled consumer attributes.
Another case example highlighting the timeliness of research enabled by the COVID-19 Research Database is work by researchers at the University of Pennsylvania and Medidata Solutions on the association of vitamin D deficiency with COVID-19.77,78 As the pandemic unfolded, studies emerged suggesting links between vitamin D deficiency and COVID risk.79 Using electronic medical records data, the researchers were able to assess associations of pre-pandemic vitamin D deficiency with risk of COVID-19 infection during the pandemic, initially in oncology populations and later in the general population among patient groups at elevated risk for vitamin D deficiency.
COVID-19 Research Database impact and perspective
The consortium enables an ongoing flow of research questions to be addressed as the COVID-19 pandemic evolves. As of May 2021, over 350 academic, scientific, and medical researchers have accessed the repository and produced over 40 publications. At the time of this writing, the consortium continues to support over 100 ongoing project research teams at any given time and is expected to continue at least through Spring 2022.
The success of the consortium has been achieved by enabling a scalable approach to integrating disparate data sets for rapid research, with applications and lessons learned relevant to future related endeavors. According to the organizers, there are several key factors that have contributed to the success of the project that may inform the development of future similar engagements. These include: structured data processing and access workflows, modularized engineering and architecture with pre-defined and validated mechanisms, an agile development methodology, inclusive governance and veto rights for stakeholders (which builds trust and willingness to participate), and sponsorship and involvement from widely respected and “neutral” figures in setting up the consortium. Aniketh Talwai cites data interoperability and governance standards as key aspects, but another “lesson learned is to prioritize scale and speed from the outset.”
Key features of the COVID-19 Research Database are listed below:71
- Extensible modularity: Structuring data processing and access workflows as independent modules with pre-defined and validated mechanisms to add in new data feeds and end-users
- Security by design: Structuring data access to be locked down by default with physical impossibility of unauthorized extraction mitigates concerns about protection of intellectual property
- Agile methodology: An iterative product development approach with new features and data introduced on a rolling basis reduces time-to-access and prevents roadblocks from derailing broader effort
- Automation to scale: Investing in upfront automation of the data ingestion, linking, and provisioning processes allows for rapid growth in both users and data
- Structured onboarding: Proactively anticipating challenges in end-user experience and mitigating them through comprehensive onboarding process and collateral
- Stakeholder rights: Inclusive governance committee and veto rights on core interests builds trust and willingness to participate
- Credible convener: Sponsorship and involvement from widely respected and “neutral” figures in setting up the consortium ensures openness to engage
- High-bar wide-scope for applications: Allowing end-users latitude to explore a wide range of use-cases and research topics, but enforcing bar on quality of output